Within the “Data Review and Matching” page (you’ll find it under Program Indicators in the main menu on the left-hand side of your page), you will see three tabs that outline three steps:
Step 1: Match Indicators
Step 2: Match Disaggregations
Step 3: Match Data Sets

Let’s review each step:
Step 1: Match your Project Indicators
You my have already matched your Program indicators to your Project indicators when you created the indicator, but you can review your matches again on this page.
You can choose to Match by Indicators, or Match by Projects. The Match by Projects function is useful in case you have recently added a new Project to your Program and want to see all the relevant indicators to match in that Project.
Matching by Indicators allows you select the Program indicator, and the details will appear below – alongside the list of Project indicators it is currently linked to.
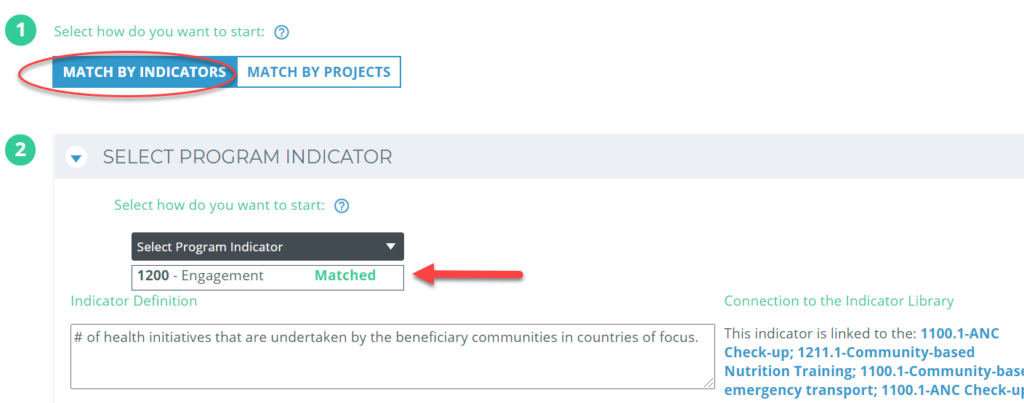
Matching by Project allows you to see all your projects connected to your program and can expand or collapse each to see its list of indicators.
Find the ones you want to match, choose which program indicator to match it to, and select “Add new match”.
Indicators that are already matched at the program level will say so as well.
Step 2: Create and match Program Indicator Disaggregation’s to the ones from a Project level
First, select a Program indicator you want to work with from the drop-down menu.
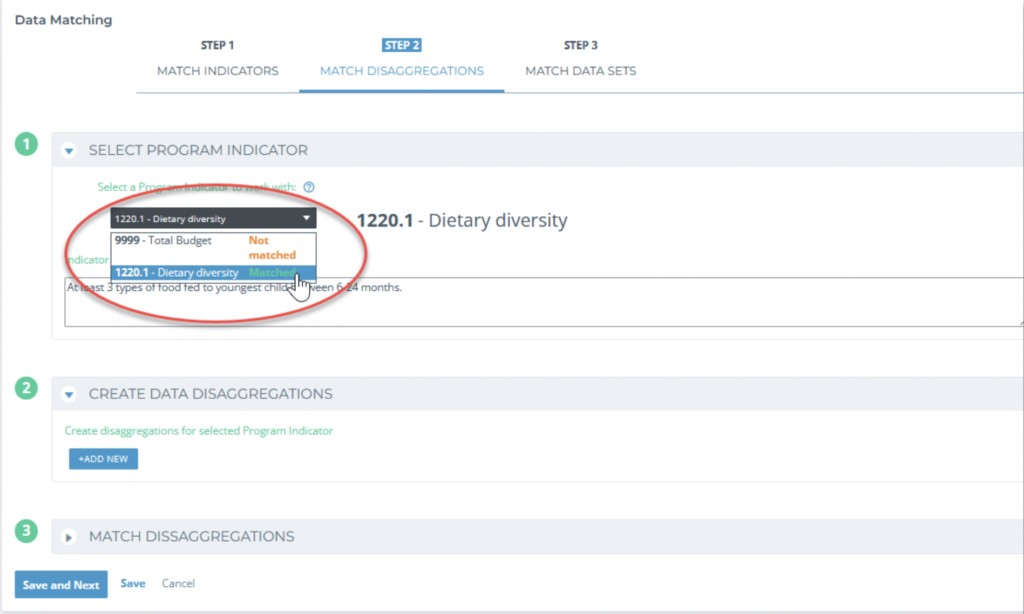
Next, you can add in the desired disaggregations that will show in the Program Report (1). You can think of these labels like the disaggregation rows in the calculations for other indicators. You can also give it a custom colour.
Once this is done, you can scroll down to your third task, “Match disaggregations”. For each Project, you need to select which relevant Data Collection Tools you’d like to include in the aggregation. Start by choosing a Project and selecting the relevant data collection tool from the columns (2).
You will see a group of results disaggregations for each Project indicator. You want to use this matching step to make sure that Kinaki understands which groups of results are associated across different Projects even if they may have different names. For example, one project may have data with different terminology, such as “Men” or “Male”, and “Women” or “Female”. You can combine this data together by matching with the relevant disaggregation at the Program-level. You can drag and drop the entries into the correct row under the data collection tool for this step (3).
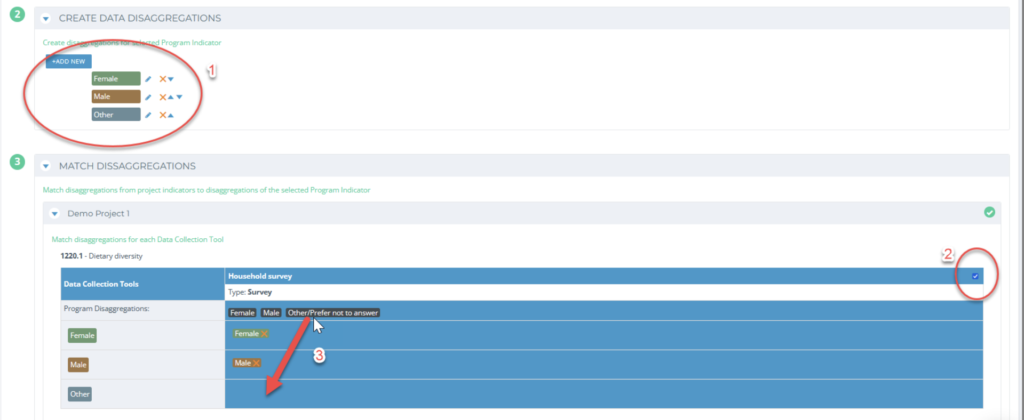
In the example below, you can see how multiple disaggregations from this Project’s data collection tool were combined to match the Program-level disaggregations:
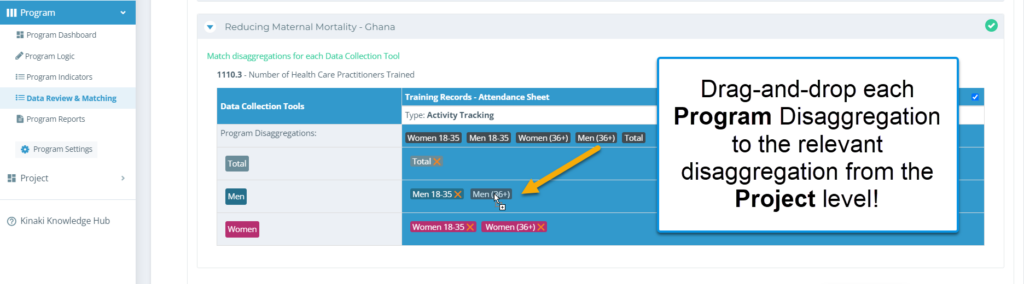
Complete this step for the other Projects in your Program.
Other projects may not have any disaggregation. In which case Kinaki creates automated total, that represents all results under that data collection tool.
Some Projects may not have any associated data collection tools, or have no existing data sets yet. In these cases, you will be unable to do any matching at this point. But you can come back later, once the data set for the Project is submitted.
Let’s look at “Step 3: Match Data Sets” in the next article.